
[Programming Language] Syntax, Grammer
사전지식
- 프로그램은 statements로 구성되어있다.
- Statement는 다음과 같이 구성됨.
- Expressions
- variables, operators and method calls
- Declarations
- Control flow
- Expressions
- Statement는 natural language에서 대략적으로 하나의 sentences와 같다.
- aValue = 3922.1234(assignment statement)
- Object myobjct = new Object(); (object creation statement)
- 하나의 statement forms은 프로그램 실행 단위이다.
Introduction
Syntax : expressions, statements, and program units의 구조 또는 형태
Semantics : expressions, statements, and program units의 의미
Syntax와 Semantics는 language의 정의를 제공한다.
Syntax를 설명하기위해 필요한 개념
- Language는 sentences의 집합이다.
- sentence는 알파벳으로 구성된 문자열이다.
- Lexeme은 language에서 가장낮은 문법적 단위이다.
- ex) *, sum, begin
-
Token은 lexemes의 category이다.
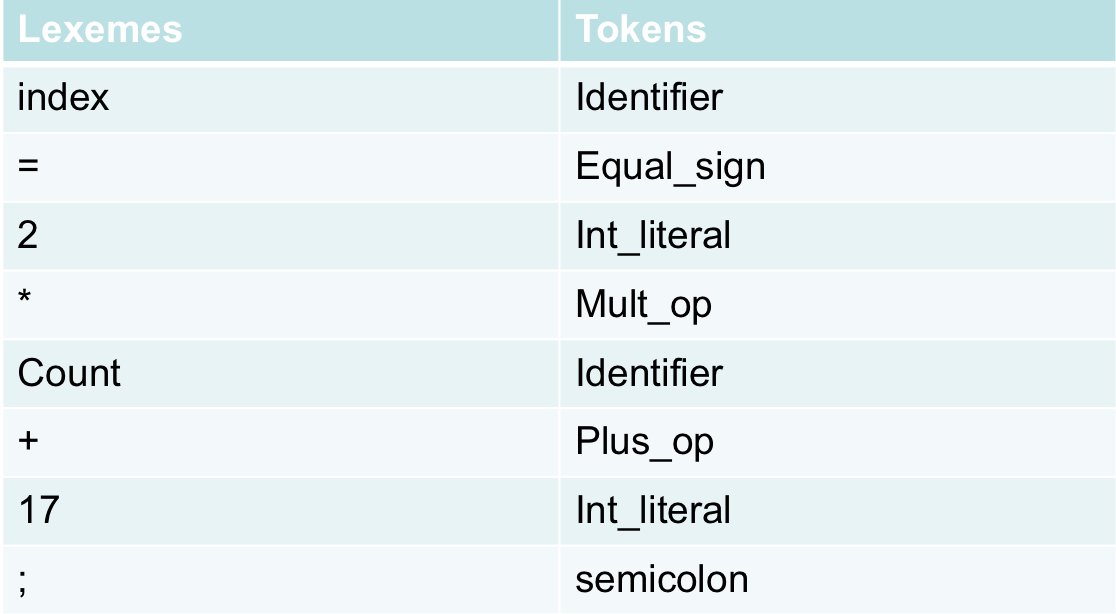
Compilation Steps
- Preprocessing
- #include, #define와 같은 전처리 기호를 처리하는 단계
- Compilation(or Interpretation)
- high-level language을 machine language로 변환시키는 단계
- Assembling
- 어셈블리어를 binary code로 번역한다.
- Linking
- binary code들을 하나로 이어준다(startup code와 필요한 라이브러리 포함)
The Stages of Compilation
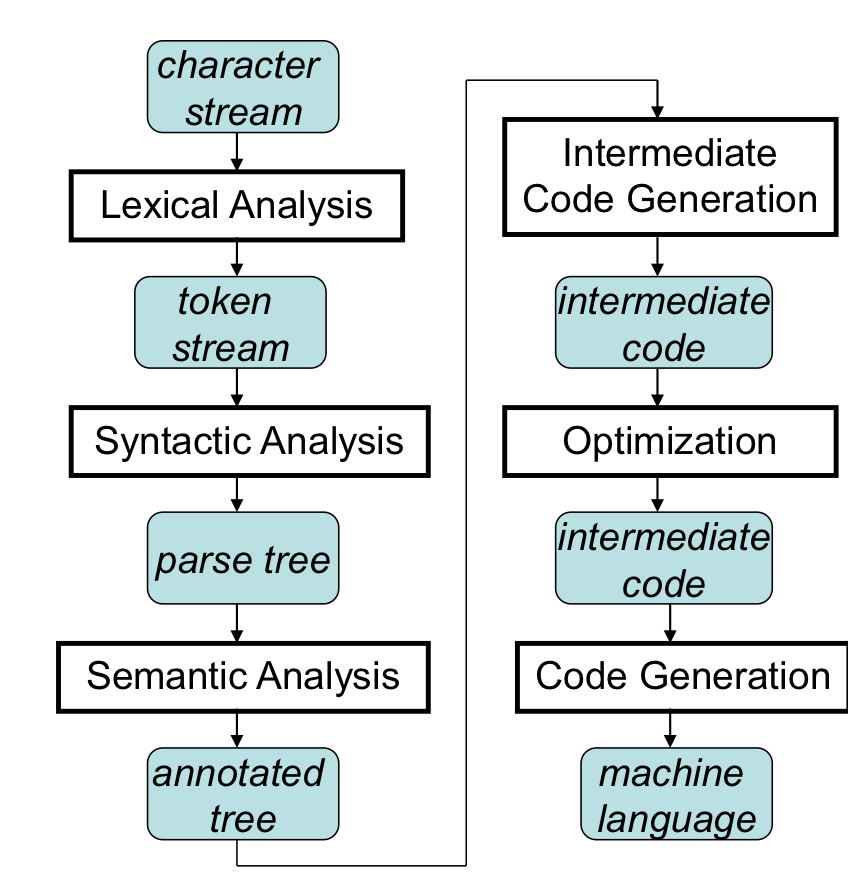
위에서 설명한 컴파일 단계를 조금더 세분화 하면 위의 그림과 같다.
- Lexical analysis
- lexer(scanner)가 character stream을 받아서 sentence tokenizing을 수행하고 token stream을 만들어낸다.
- Syntactic analysis
- syntactic analyzer(parse)가 이전 단계에서 생성된 token stream을 받아서 정의된 grammer에 맞는 phrases로 grouping한다.
- parser가 parse tree를 생성한다.
- Semantic Analysis
- 이 단계에서는 syntactic anlysis에서 하지못한 의미적 분석을 포함한다. type checking, variables declaration문제 등을 Attribute grammers라는 방법을 이용해서 parse tree에 의미정보를 담을 수 있도록 해서 위의 문제들을 해결한다.
- Intermidiate Code Generation
- Attribute Grammer 정보를 이용해서 byte code를 생성해낸다.
- Optimization
- Inlining
- Local optimizations
- Control flow optimizations
- Global optimizations
- Native code generation
위의 방법들을 이용해서 코드 최적화를 진행한다. 자세한 설명은 추후 포스팅에 추가할예정.
- Code Generation
- 최종적으로 Optimization 단계에서 Native code generation을 통해 각 machine에 적합한 machine language를 생성해낸다.
우선 Syntactic analysis가 어떻게 이루어지는 더 자세히 알아보기 위해 Parser에서 필요한 개념들을 자세히 알아볼 필요가 있을것같다. 먼저 Grammer를 정의하기 위해 필요한 BNF부터 알아보자.
BNF(Backus–Naur Form)
BNF에서 abstractions은 syntactic structures에 대한 classes를 표현하기위해 사용된다. 여기서 abstractions란 syntatic variables인데 이것은 nonterminal이라고 보아도 무방하다.
BNF에서 lexemes 또는 tokens은 terminals이다. 두가지 rule이 존재하는데 left-hand-side(LHS)와 right-hand-side(RHS)가 있다. LHS는 BNF에서 왼쪽에 위치하며 하나의 nonterminal만 올 수 있고, RHS의 경우 nonterminal, terminal 모두 존재할 수 있다.
BNF의 기본 형태는 아래와 같다.
<if stmt> -> if <logic_expr> then <stmt>
보통 BNF는 조금 더 표현을 편리하게 사용할 수 있도록 확장된 EBNF를 사용해서 표현한다.
EBNF 표현법
[ ]기호는 기호안에 있는 표현식을 선택할 수 있도록 한다.- { } 는 반복을 의미한다. { } 안에 표현식은 무한정 반복될 수 있고 생략될 수 있다.
|는 여러 가지의 표현식 중 하나를 사용한다는 의미이다.
사용 예시
BNF
<expr> -> <expr> + <term> | <expr> - <term> | <term>
<term> -> <term> * <factor> | <term> / <factor> | <term>
<factor> -> <exp> ** <factor> | <exp>
EBNF
<expr> -> <term>{(+|-) <expr>}
<term> -> <term>{(*|/) <factor>}
<factor> -> <exp> {** <factor>}
BNF와 EBNF가 무엇인지 알아보았다. 그렇다면 Syntactic Analysis와 BNF는 무슨 관계가 있는것일까?
BNF의 용도는 token stream으로 부터 각각의 token들이 grammer에서 정의한 class에 알맞게 grouping되는지를 확인하기 위해 사용되는 abstractions이라 했다. 만약에 어떠한 sentence가 존재하고 해당 sentence를 syntax tree로 나타낼 수 있다면(derivation) 해당 sentence는 우리가 정의한 grammer에의해 생성된 language 집합에 속하게 되어 문법적으로 오류가 없다는것임을 알 수 있을것이다. 그렇다면 해당 statement가 grammer에 의해 생성될 수 있는 문장인지 어떻게 알 수 있을까?
derivation을 해보면 된다.
Derivation
- grammer가 어떻게 sentence를 생성하는지 확인하는방법
- start symbol로 부터 어떠한 sentence를 생성할 수 있다면, 해당 sentence는 grammer에의해 표현가능한 language의 일부분인것.
- Derivation은 nonterminal들을 replacing하면서 진행된다.
Derivation 예시

위의 Derivation은 parse tree로도 나타낼 수 있다.
Leave a comment